tl;dr — We served Qwen 3.5 27B on two AWS instance types (Intel Xeon + Nvidia GPU and AMD EPYC + Nvidia L40S) using a dynamic scheduler with a custom runtime. By co-executing across both CPU and GPU on a single node, we achieved nearly +50% capacity with no additional GPU spend.
The Awkward Middle
Most LLM serving decisions reduce to a simple fork: scale horizontally across more GPUs, or live within the latency floor of a single card. For dense models at 70B+, multi-GPU is obviously necessary. For sub-7B models, a single GPU is obviously sufficient. But Qwen 3.5 27B sits in neither camp — it’s what we’ve started calling the awkward middle.
For our OpenClaw Beta, we needed to serve Qwen 3.5 27B at production scale. We started with what most teams do in the absence of a high-speed interconnect like NVLink: a two-node Pipeline Parallelism (PP-2) setup. For a dense 27B model, inter-node synchronization overhead was a significant fraction of total execution time.
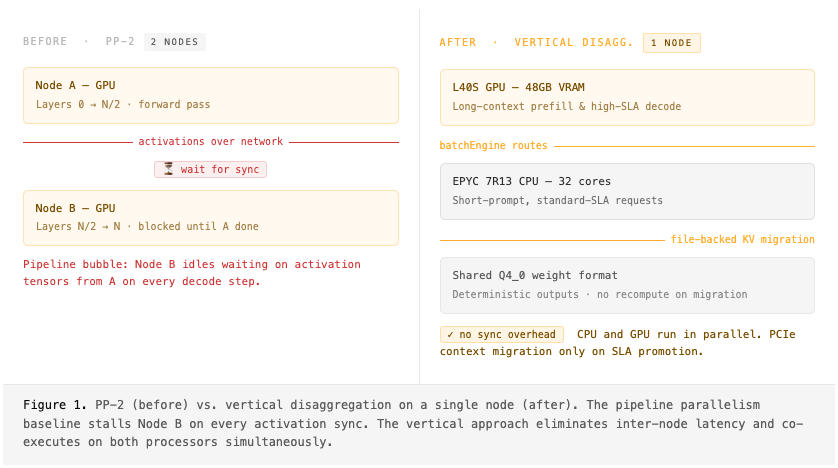
The culprit is structural. Pipeline Parallelism introduces a strict latency dependency: Node B cannot begin executing until Node A finishes its forward pass and transmits activations across the wire. We were spending a sizable fraction of each decode step waiting on network synchronization — a pipeline bubble on every token.
We pivoted. Instead of scaling out, we asked: what can we saturate within a single node?
The answer became vertical disaggregation — one node, two processors working in parallel. The L40S GPU (48GB VRAM) handles long-context prefill and high-SLA decode. The EPYC 7R13 CPU (32 cores) handles short-prompt, standard-SLA requests. Both share a single Q4_0 weight format, so sessions can migrate between backends without recomputation. The only cross-processor cost is PCIe context migration on SLA promotion — paid once, not per token.
Heterogeneous Routing: the batchEngine
The core of our approach is batchEngine — an SLA-aware scheduler that does intelligent routing based on SLA tier, context length, and other runtime parameters. For long-context prefills, the GPU’s massively parallel CUDA and tensor cores are indispensable. But for short-prompt, standard-SLA requests, the GPU is overkill: you’re paying for parallelism you can’t use, and interrupting high-throughput batches to service what amounts to a few hundred tokens.
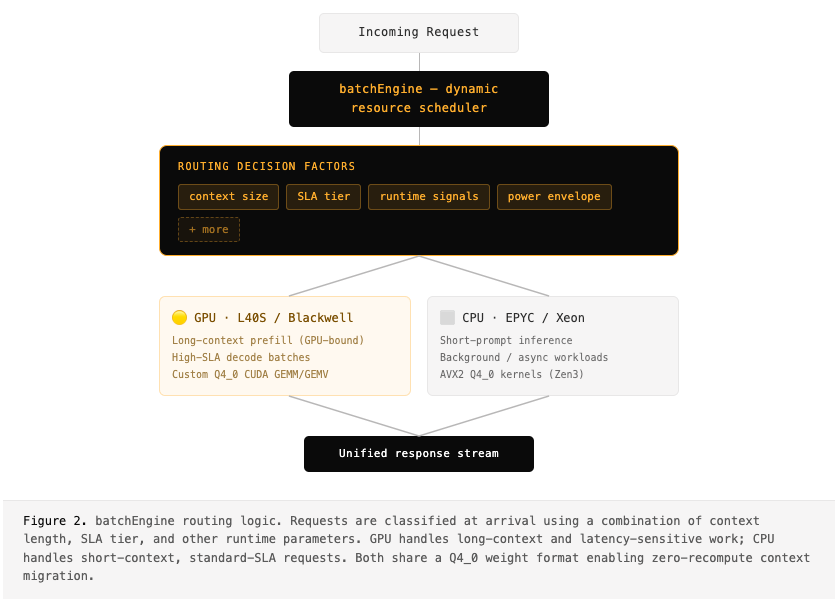
Every Cycle Counts: Custom Kernels
Routing requests to the CPU only matters if the CPU can execute them competitively. Off-the-shelf BLAS libraries weren’t going to cut it — designed for FP32/FP64, not quantized inference. We needed custom kernels tuned to Q4_0 and the EPYC 7R13’s specific ISA.
One deliberate constraint anchors the entire design: we use the same Q4_0 weight format across both CPU and GPU paths. This ensures deterministic outputs — a request can be migrated between backends at prefill and decode boundaries without any recomputation.

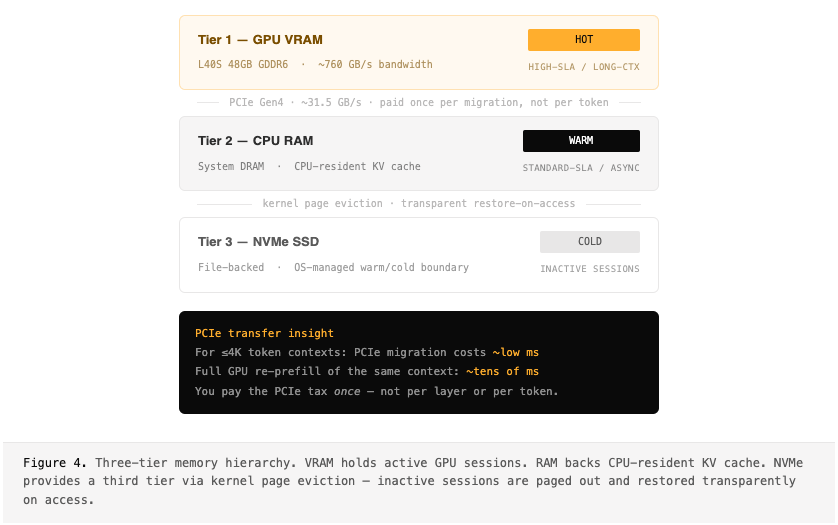
Context Migration Between Processors
The hardest problem in heterogeneous serving isn’t routing or kernels — it’s the context. If a session’s KV cache lives in GPU VRAM when its next request needs to run on the CPU, you either need a copy or a recompute. Neither is acceptable at scale.
We solved this with a file-backed KV cache. Context is migrated into each processor’s memory just before it’s needed, yielding a natural three-tier memory hierarchy managed transparently by the OS:
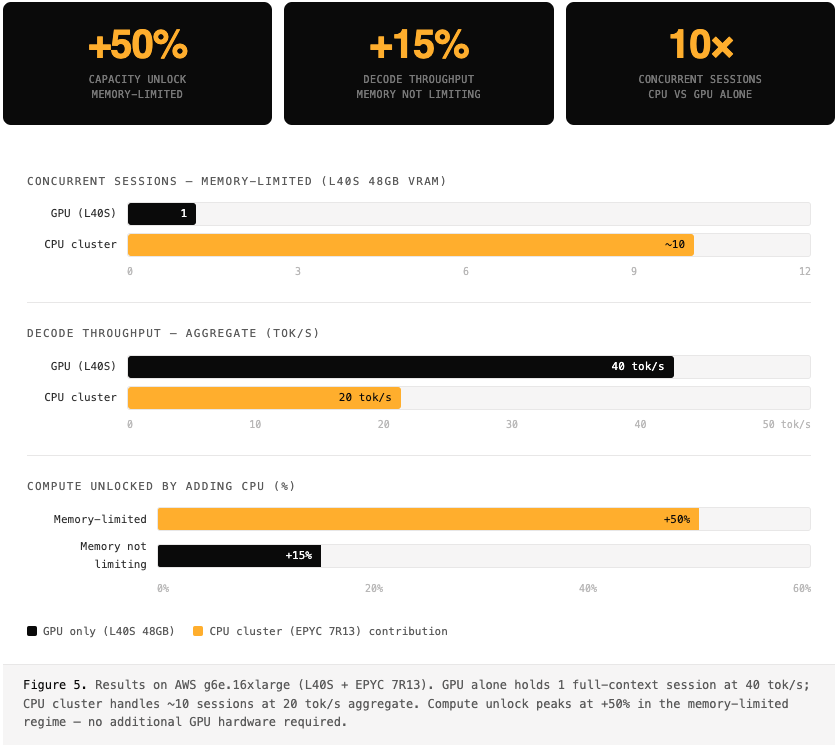
Results
Moving from PP-2 to single-node vertical disaggregation had measurable impact across all metrics that matter for production serving.
Conclusion
The standard mental model for LLM serving treats CPU and GPU as separate concerns: the CPU manages orchestration, the GPU runs inference. This leaves a significant fraction of node compute untouched.
By building an SLA-aware scheduler with optimized kernel backends and context migration, we treated the CPU as a genuine inference co-processor — one that frees the GPU to focus exclusively on workloads that justify its cost. The result isn’t just higher throughput; it’s a more efficient system with more predictable latency, which matters as much as raw capacity in production.
The broader principle: before reaching for another GPU, audit the silicon you already have.