At OpenInfer, we’re dedicated to pushing the boundaries of what’s possible with large language models (LLMs). These models, while immensely powerful, often come with hefty hardware demands that can be a barrier to innovation. That’s why our team has been laser-focused on developing memory optimizations that make running these models more accessible and efficient. Today, we’re excited to share how our latest advancements are reshaping the way LLMs are deployed.
The Problem: High Memory Demands
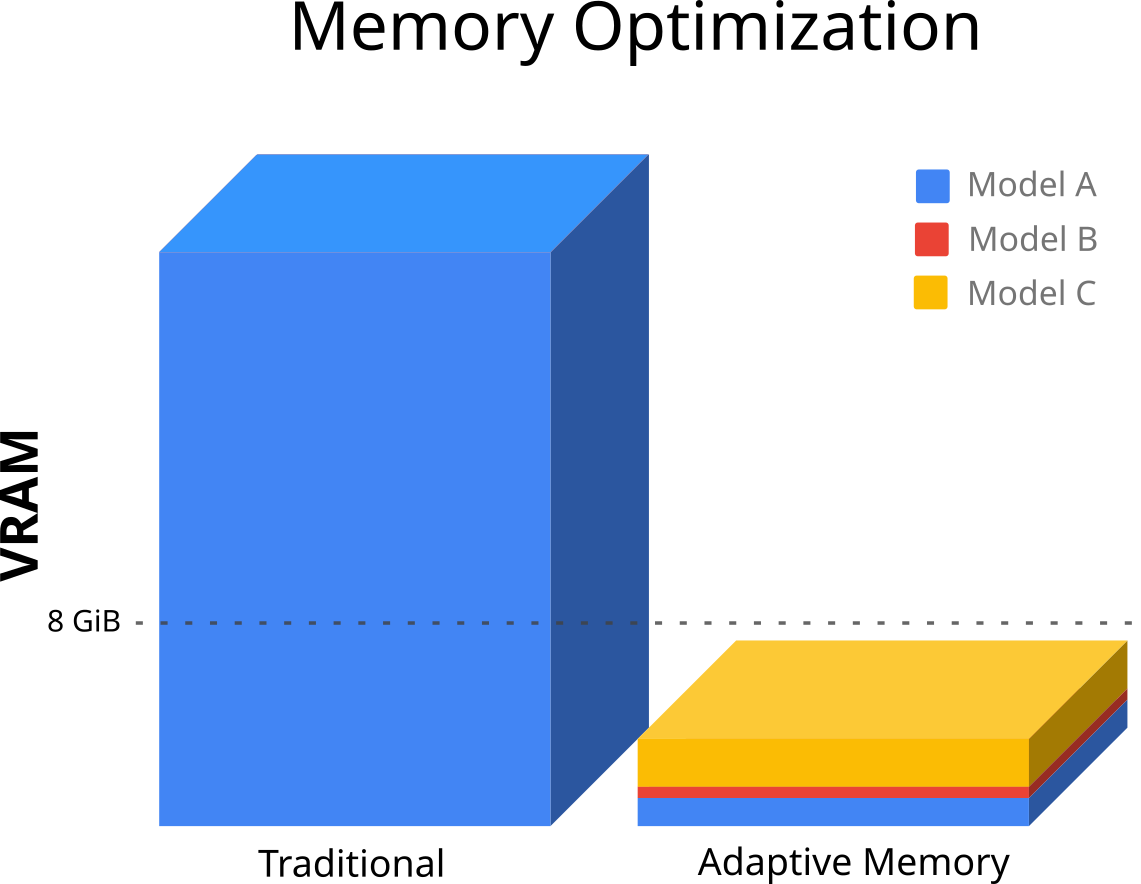
Running large models has traditionally required substantial amounts of VRAM, making it challenging to scale or experiment with multiple models simultaneously. For instance, models with extensive context windows—critical for tasks like document summarization or code generation—can consume tens of gigabytes of VRAM. This limits their use to only the most powerful (and expensive) hardware setups.
The Solution: OpenInfer’s Memory Optimization Engine

In our previous video, we demonstrated how OpenInfer’s engine enables running models with larger context windows using a fraction of the VRAM. Specifically, we showcased a setup where a 14GB context was processed with just a few hundred megabytes of VRAM—a feat that seemed almost unthinkable just a few years ago.
How did we do it? Our engine employs cutting-edge techniques like:
- Dynamic memory swapping: Offloading inactive parts of the model to system memory or disk without disrupting performance.
- Efficient tensor compression: Reducing memory overhead by optimizing data representations.
- Granular memory management: Ensuring only the most critical operations remain in VRAM at any given moment.
These innovations not only reduce VRAM usage but also make it feasible to run large models on consumer-grade GPUs or even in shared cloud environments.
The Next Step: Concurrent Model Execution
One of the most exciting implications of our optimizations is the ability to run multiple large models concurrently. Traditionally, deploying multiple models on the same hardware would lead to resource contention, often requiring compromises in model size or performance. But with OpenInfer, each model’s VRAM footprint is so small that you can seamlessly run several side by side.
Imagine a scenario where a developer can:
- Run a code-generation model alongside a conversational AI for live debugging.
- Deploy specialized models tailored to different domains in parallel—all on a single GPU.
- Experiment with ensemble approaches, where multiple models collaborate to improve accuracy, without worrying about VRAM limitations.
This capability unlocks new possibilities for applications that demand high throughput, flexibility, and multitasking—from AI-powered customer support systems to real-time analytics pipelines.
What’s Next?

As we continue refining OpenInfer’s memory optimization engine, our goal is to democratize access to large models, empowering developers and organizations to do more with less. Whether you’re a researcher pushing the frontiers of AI or a startup integrating advanced models into your products, OpenInfer’s innovations are here to support your journey.
Below video has captured a live demo of the multi agent feature.
Stay tuned for more updates, and if you haven’t already, check out our previous demonstration to see these optimizations in action. We’re excited to hear your thoughts and learn how you’re using OpenInfer to bring your ideas to life.